Identifying transportation units (TUs) is essential for improving the efficiency of port logistics. However, progress in this field has been hindered by the lack of publicly available benchmark datasets that capture the diversity and dynamics of real-world port environments. To address this gap, we present the TRUDI dataset-a comprehensive collection comprising 35,034 annotated instances across five categories: container, tank container, trailer, ID text, and logo. The images were captured at operational ports using both ground-based and aerial cameras, under a wide variety of lighting and weather conditions. For the identification of TUs-which involves reading the 11-digit alphanumeric ID typically painted on each unit-we introduce TITUS, a dedicated pipeline that operates in three stages: (1) segmenting the TU instances, (2) detecting the location of the ID text, and (3) recognising and validating the extracted ID. Unlike alternative systems, which often require similar scenes, specific camera angles or gate setups, our evaluation demonstrates that TITUS reliably identifies TUs from a range of camera perspectives and in varying lighting and weather conditions. By making the TRUDI dataset publicly available, we provide a robust benchmark that enables the development and comparison of new approaches. This contribution supports digital transformation efforts in multipurpose ports and helps to increase the efficiency of entire logistics chains.
The standardisation of Intermodal Loading Units (ILUs), such as containers, semitrailers and swap bodies, has revolutionised global trade yet their efficient and robust identification remains a critical bottleneck in high-throughput ports and terminals. This paper reviews 63 empirical studies that propose computer vision (CV) based solutions. It covers the last 35 years (1990-2025), tracing the field’s evolution from early digital image processing (DIP) and traditional machine learning (ML) to the current dominance of deep learning (DL) techniques. While CV offers cost-effective alternatives for other types of identification techniques, its development is hindered by the lack of publicly available benchmarking datasets. This results in high variance for the reported results such as end-to-end accuracy ranging from 5 % to 96 %. Beyond dataset limitations, this review highlights the emerging challenges especially introduced by the shift from character-based text recognition to scene-text spotting and the integration of mobile cameras (e.g. drones, sensor equipped ground vehicles) for dynamic terminal monitoring. To advance the field, the paper calls for standardised terminology, open-access datasets, shared source code, while outlining future research directions such as contextless text recognition optimised for ISO6346 codes.

This paper focuses on storage strategies for loading units (LUs) in inland ports, which, despite being critical logistics hubs, are often overlooked in comparison to standardized seaport operations. Through a structured, PRISMA-based literature review and comparative analysis, the paper aims to identify efficient, flexible storage approaches tailored to the needs of small- to medium-sized inland ports. The objective is to address a research gap and provide practical recommendations to enhance the operational efficiency and competitiveness of inland logistics.

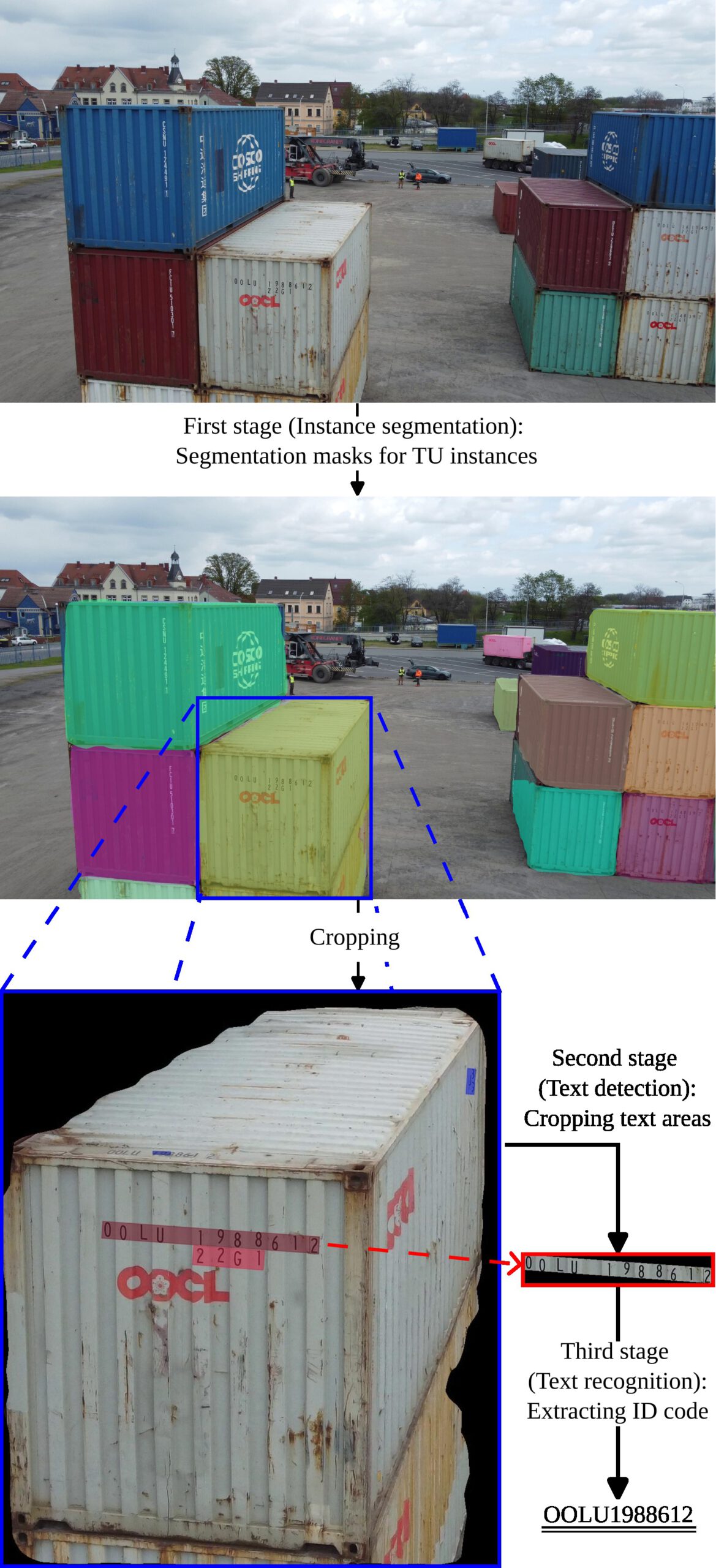
This study presents a framework for inland ports that uses unmanned aerial vehicle (UAV)-based imaging, and reach stacker sensor data including a camera to monitor port operations. A three-stage identification pipeline detects transportation units (TUs) as the first stage, then markings of detected TUs such as ISO6436 compliant ID codes are detected as the second stage. Finally, a text recognition model extracts their IDs.

This paper introduces a novel application utilizing drones and deep learning to identify containers and semi-trailers, enhancing inland port operations. With this drone-based image and text recognition system, the basic condition of the yard/storage area can be determined at any time without using (human) labor, eliminating the need for manual inspections. We use a two-step recognition process, first localizing the text ID and then reading/identifying it.

Poster summary of the project
An overview of the goals, staff, and tasks of the project is provided by the poster for the "Digital Total" event at the University of Hamburg.
